
Clustering — Unsupervised Learning
What is Clustering?
“Clustering” is the process of grouping similar entities together. The goal of this unsupervised machine learning technique is to find similarities in the data point and group similar data points together.
Why use Clustering?
Grouping similar entities together help profile the attributes of different groups. In other words, this will give us insight into underlying patterns of different groups. There are many applications of grouping unlabeled data, for example, you can identify different groups/segments of customers and market each group in a different way to maximize the revenue.
Another example is grouping documents together which belong to the similar topics etc.
Clustering is also used to reduces the dimensionality of the data when you are dealing with a copious number of variables.
How does Clustering algorithms work?
There are many algorithms developed to implement this technique but for this post, let’s stick the most popular and widely used algorithms in machine learning.
- K-mean Clustering
- Hierarchical Clustering
K-mean Clustering
It starts with K as the input which is how many clusters you want to find. Place K centroids in random locations in your space.
Now, using the Euclidean distance between data points and centroids, assign each data point to the cluster which is close to it.
Recalculate the cluster centers as a mean of data points assigned to it.
Repeat 2 and 3 until no further changes occur.
Now, you might be thinking that how do I decide the value of K in the first step.
One of the methods is called “Elbow” method can be used to decide an optimal number of clusters. Here you would run K-mean clustering on a range of K values and plot the “percentage of variance explained” on the Y-axis and “K” on X-axis.
In the picture below you would notice that as we add more clusters after 3 it doesn’t give much better modeling on the data. The first cluster adds much information, but at some point, the marginal gain will start dropping.
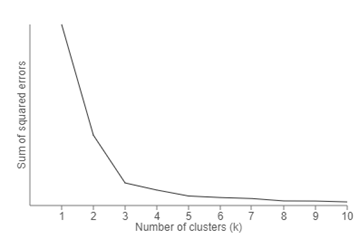
Elbow Method