Hierarchical Clustering
Unlike K-mean clustering Hierarchical clustering starts by assigning all data points as their own cluster. As the name suggests it builds the hierarchy and in the next step, it combines the two nearest data point and merges it together to one cluster.
1. Assign each data point to its own cluster.
2. Find closest pair of cluster using Euclidean distance and merge them in to single cluster.
3. Calculate distance between two nearest clusters and combine until all items are clustered in to a single cluster.
In this technique, you can decide the optimal number of clusters by noticing which vertical lines can be cut by horizontal line without intersecting a cluster and covers the maximum distance.
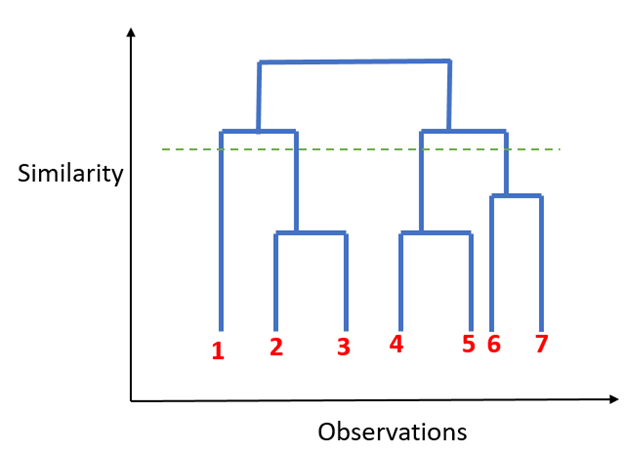
Dendogram
Things to remember when using clustering algorithm:
- Standardizing variables so that all are on the same scale. It is important when calculating distances.
- Treat data for outliers before forming clusters as it can influence the distance between the data points.